Some time ago while reading about Go concurrency I stumbled upon an information that there are many Go services running in K8s under CPU limits that are not running as efficiently as they otherwise could be.
In this post, I will show what happens when CPU limits are being used and your Go service is not configured to run within these settings.
Let’s start with a bit of theory.
K8s CPU limits
This is the K8s configuration settings that specifies how much resource a container requests and is allowed.
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
requests:
cpu: „500m"
limits:
cpu: "500m"CPU limits are enforced by CPU throttling. When a container approaches its CPU limit, the kernel will restrict access to the CPU corresponding to the container’s limit.
Limits and requests for CPU resources are measured in CPU units. A CPU unit allows you to describe fractions of CPU time. In Kubernetes, 1 CPU is equivalent to a physical CPU core, or 1 virtual core, depending on whether the node is a physical host or a virtual machine running inside a physical machine.
Fractional requests are allowed. When you define a container requesting 0.5 CPU, you are requesting half as much CPU time compared to if you asked for 1.0 CPU. It is the same value, as you would request for 500m, which can be read as five hundreds milicores or milicpus.
CPU resource is always specified as an absolute amount of resource, never as a relative amount. For example, 100m represents the roughly same amount of computing power whether that container runs on a single-core or 24-core machine.
Kubernetes does not allow you yo specify CPU with a precision finer than 1m.
Scheduler
Your program is just a set of instructions that need to be executed one after the other sequentially. To make that happen, the operating system uses a concept called THREAD. It is the job thread to sequentially execute the assignment so it will not be uncommon to call this being a path of execution.
Every program you run creates a process, and each process is given an initial thread. Thread have the ability to create more threads. All these threads run independently and scheduling decisions are made just at the thread but not process level. Threads can run concurrently (each taking a turn on an individual core) or in parallel (each running at the same time).
The program counter which is sometimes called the IP (instruction pointer), is what allows the thread to keep track of the next thread’s instruction to execute.
The thread can be in one of 3 states:
- Waiting (stopped & waiting for something),
- Runnable (thread wants a time on a core),
- Executing (thread is executing its machine instruction).
There are two types of work the thread can do. CPU-Bound when constantly computing is making and IO-Bound when is requesting access to a resource.
Context switching
The physical act of swapping threads on a core is called a context switch. A context switch happens when the scheduler pulls an Executing thread off a core and replaces it with a Runnable one. The selected thread moves into an Executing state, the pull thread moves back into either Runnable or Waiting state.
Context switch are considered to be expensive, the amount of latency incurrent takes between 1000 – 1500 ns. If your program is focused on IO-Bound, it is desirable have context switches, but if your program do CPU-Bound work, then the switches are a performance nightmares.
As an example, if you have one core, define your scheduler period to be 1000ms and you have 10 threads, then each thread gets 100ms each. If you have 100 threads, each thread gets 10ms each. However, the more threads you have, the percentage of context switch grows and can disturb the computation.
The Go scheduler
When the Go program starts up, it’s given a Logical Processor P for every virtual core that is identified on the host machine. If you have a processor with multiple hardware threads per physical core, each hardware thread will be presented to your Go program as a virtual core.
To test the virtual cores, consider the following program:
package main
import (
"fmt"
"runtime"
)
func main() {
// NumCPU returns the number of logical
// CPUs usable by the current process.
fmt.Println(runtime.NumCPU())
}Any Go program I run on my machine will be given 11 P’s by default. Every P is assigned an OS thread M ( ‘M’ stands for machine). This thread is managed by the OS, and the OS is responsible for placing this thread on a core for execution.
Every Go program is also given an initial goroutine G, which is the path of execution for a Go program. We can think of goroutine as an application-level threads. Just as OS threads are context-switched on and off a core, goroutines are context-switched on and off an M.
The Go scheduler is part of Go runtime, the Go runtime is built into your application.
Goroutine states
Just like threads, goroutines have the same three high-level states:
- Waiting,
- Runnable,
- Executing.
The Go scheduler requires well-defined user-space events that occur at safe points in the code to context-switch from. These events and safe points manifest themselves within function call. Function calls are critical to the health of Go scheduler. It’s critically important that function calls happen within reasonable timeframes.
There are four classes of events that occur in Go programs that allow the scheduler to make the scheduling decisions. These are:
- The use of the keyword go: this is how you create a goroutine,
- Garbage collection,
- System calls,
- Synchronisation and orchestration: if an atomic, mutex or channel operation call will cause the goroutine to block, the scheduler can context-switch a new goroutine to run.
Asynchronous & synchronous system calls
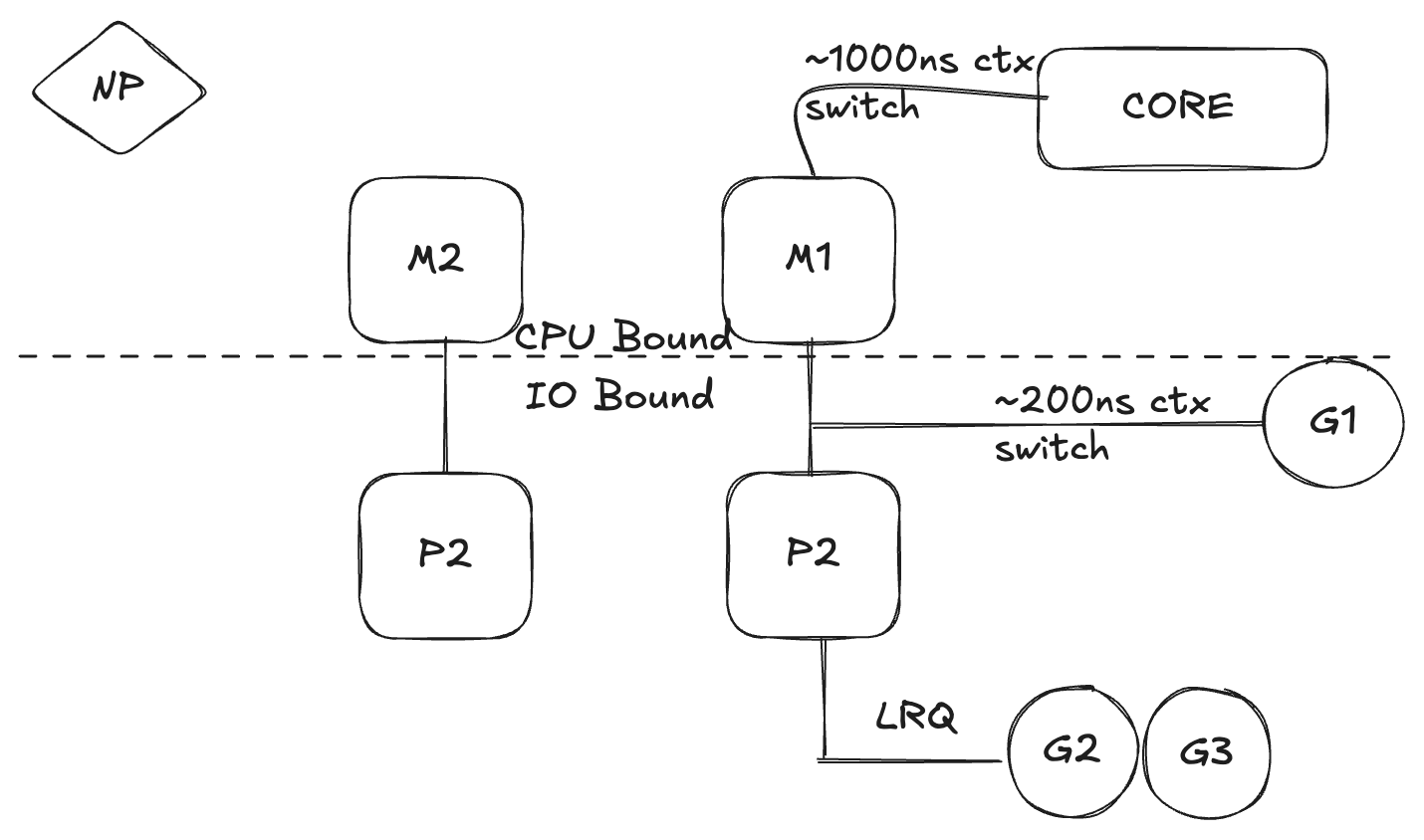
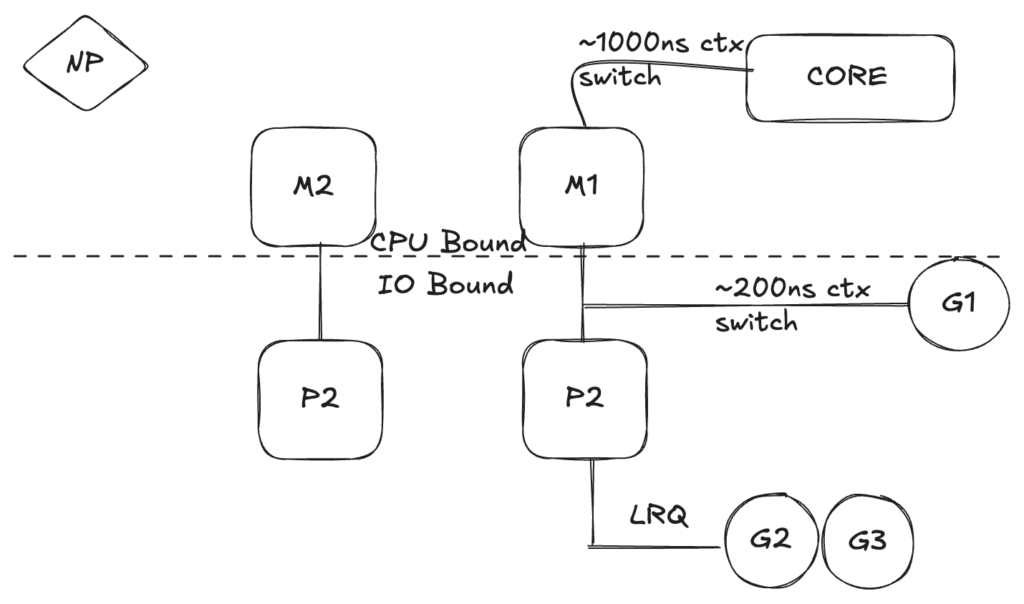
When the OS you are running on has the ability to handle a system call asynchronously, something called the network poller (NP) can be used to process the system calls more efficiently. If G1 is running on M1 and wants to make a network call, the G1 is moved to the network poller and the asynchronous network system call is processed. Once the G1 is moved to the NP, the M1 is now available to execute a different goroutine, G2 is context-switched on the M. Once the asynchronous network system call is completed, the G1 is moved back into the queue.
If the goroutine G1 wants to make a synchronous system call, the G1 is going to block the M1. This is unfortunate but there’s no way to prevent this from happening; one example is a file-based system call. The M1 is moved off the P with the blocking G1 still attached. A new M2 is brought in and G2 is context-switched into. Once the blocking call is completed, the G is moved back to the queue and M1 is saved for future use.
Work stealing scheduler
The last thing you want is an M move into a waiting state because, once that happens, the OS will context-switch M off the core. This means that P can’t get any work done, until M is context-switched back on a core. The work stealing also helps to balance goroutines across all the P’s.
Assume, there are 2 P’s having their own goroutines queues. If P1 services all the goroutines quickly, it checks the P2 queue or the global goroutine queue to get the work and become idle.
Concurrency in Go
Concurrency means „out of order“ execution. Taking a set of instructions that would otherwise be executed in sequence and finding a way to execute them out of order and still produce the same result.
Concurrency is not the same as parallelism. Parallelism means executing two or more instructions at the same time.
Workloads
How do you know when out of order execution may make sense? As it has been listed above, there are two types of workloads to understand:
- CPU-Bound: this is a workload that never creates a situation where goroutine naturally move in and out of Waiting state, e.g. a thread calculating Pi to the Nth digit,
- IO-Bound: this is a workload that causes the goroutine to naturally enter into Waiting state.
With CPU-Bound workloads you need parallelism to leverage concurrency; one OS thread is not efficient since the goroutines are not moving in and out of waiting states. Having more goroutines than there are OS/hardware threads can slow down workload execution because of the latency cost of moving goroutines on and off the OS thread.
With IO-Bound workloads you do not need parallelism to use concurrency. Your workload is naturally stopped and this allows a different goroutine to leverage the same OS/hardware thread efficiently instead of letting the OS/hardware thread sit idle.
Go programs are CPU bound
What’s important is that the Go scheduler takes IO bound workloads (executed by G’s on M’s) and converts them into CPU bound workloads (executed by M’s on Cores). This means your Go programs are CPU-Bound and this is why the Go runtime creates by default as many OS threads as there are cores on the machine it’s running on.
If you do not set GOMAXPROCS, then the Go service will use as many OS threads (M) as there are cores on the underlying machine, being unaware of the restrictions imposed by the K8s orchestrator.
Prove with code
To prove that it is important to take GOMAXPROCS into account, I have created a dedicated repository https://github.com/huberts90/gomaxprocs-K8s and run the code with different setup. The task is a CPU-Bound computing run concurrently by N goroutines defined with an NUM_GOROUTINES environment variable. The number of logical processor P is controlled with GOMAXPROCS environment variable. The container has been limited to the 250m or 1250m CPU units.
The machine the tests were executing on has 11 CPUs and the K8s node has been limited to 4 CPUs.
Across 1000 runs—with NUM_GOROUTINES set to 10 and GOMAXPROCS modified—the following results were obtained:.
| GOMAXPROCS | Limit: 250m CPU | Limit: 1250m CPU |
| 1 | Average: 18.31350ms | Average: 2.84986ms |
| 2 | Average: 26.40170ms | Average: 2.38079ms |
| 3 | Average: 31.90490ms | Average: 2.59608ms |
| 4 | Average: 34.97569ms | Average: 2.70677ms |
| 6 | Average: 44.19429ms | Average: 4.1406ms |
| 11 | Average: 45.69848ms | Average: 6.89712ms |
Takeaway
This is critically important to understand that Go programs run as CPU bound programs. When you have a CPU bound program you never want more OS threads than you have cores to avoid context-switch operations. The table above proves that the most efficient results were achieved for the GOMAXPROCS adjusted to the number of available CPUs.